![]()
Tracking Transmeta
By Van Smith
Date: July 15, 2003
![]()
Started in 1995 by Dave Ditzel, Transmeta is a company whose financial history graph looks like an icy ski run straight down to Hell. Less than three years ago, the Santa Clara, California company's IPO exploded like the sunny Indonesian island of Krakatoa. Soon there were even rumors abounding that Transmeta would use some of its newfound pocket change to gobble up AMD. But since then, Transmeta's stock has cooled so much that the cryogenic certificates could be stuffed into a duer to refrigerate liquid nitrogen. That's what hemorrhaging well over $100 million dollars a year can do to a tiny company that now has fewer than 300 employees and brought in under $25 million of total revenue in 2002.
What has happened to the company that was once the high flying rock star of the x86 world? Why was Tranmeta ever so highly valued in the first place? Does the CPU firm's Crusoe line of processors have any merit? Can Astro, Tranmeta's ambitious successor to Crusoe, save the company from what appears to be an inevitable plunge off financial cliffs into bankruptcy?
===================================
Confronting Menacing Thermals
Over the years, microprocessors have reached ever increasing clock speeds. However, megahertz is only part of the raw performance of today’s modern CPU designs. With the exception of the Intel Pentium 4, each successive CPU generation has become more efficient, taking fewer and fewer clock ticks per instruction.
The acme of this trend in the x86 world is Advanced Micro Devices’ newly introduced Opteron series of server and workstation microprocessors. The Opteron can can average four, five or even more instructions each time its clock advances a beat. To accomplish this bit of magic, the Opteron is “superscalar” meaning that the chip contains several duplicate (or complementary) execution units and multiple pipelines.
However, even with these extra execution units, the chip needs sophisticated circuitry that can recognize instructions suitable to be executed safely at the same time without undermining the intent of the original programmer. Often this means that instructions will actually be executed out of order.
An “out of order” processor introduces quite a lot of complexity, which is why a company like VIA-Centaur still uses a simple in-order design in its C3 line of chips.
Increased complexity of out-of-order superscalar microprocessors means greater design and debug efforts, increased transistor counts and correspondingly inflated energy budgets. Worse, each additional transistor contributes to the heat produced by the chip leading to a situation where chips like the Athlon XP and Pentium 4 have clock speeds limited by the amount of heat these chips produce.
This problem becomes even more acute as CPUs move to smaller process technologies. As die sizes shrink, chips have less surface area to dissipate heat. This problem is known as “thermal density” and is one of the most significant issues facing new and future chip designs.
===================================
VLIW
Anticipating looming thermal density problems, a school of thought arose that was in some ways similar to the RISC movement that waned roughly a decade earlier. Seeking to simplify chip designs, some engineers sought to strip out the complicated instruction scheduling apparatus of competing out-of-order superscalar microprocessors. However, to continue the trend for reaching higher and higher processing efficiencies, many execution units would be included. To keep these execution units all busy the designers hoped that software compilers would become sophisticated enough to submit instructions in batches.
Traditional processors read instructions, at least initially, one at a time. For most modern x86 chips, each instruction “word” is 32-bits long. For chips that access “batches” of instructions, each “word” is very long, containing most often four instructions. Accordingly, CPUs that digest batches of instructions all at once are called “Very Long Instruction Word” processors, abbreviated “VLIW.”
VLIW processors were supposed to be simpler and cheaper to design, yet provide high performance. Scalability was also a target, with each successive chip generation able to extract greater processing efficiencies simply by adding more execution units.
However, the performance of VLIW chips pivoted upon compiler technology. VLIW proponents assumed that software compilers would be able to compete with the sophisticated out-of-order circuitry in traditional processors by finding ways to bundle instructions two, three, four or more at a time.
For some applications, the value of VLIW was clear from the beginning. Many digital signal processors (DSPs) are VLIW. These chips perform the same operation (or set of operations) on reams of data, so scheduling instructions is not an issue.
However, the chips that serve as the brain power for personal computers are general purpose microprocessors. For PC's, x86 chips churn through instruction flows that are typically neither easy to predict nor simple to bundle in parallel beforehand.
More onerous, the success of any general purpose VLIW processor would ultimately depend upon the development of new, sophisticated, unproven compiler technology. Of course most of the compilers would have to be produced by groups outside of the company developing the chip.
===================================
The Transmeta Crusoe

One of the first organizations to attempt to create a VLIW general purpose microprocessor was Transmeta. Recognizing that it was folly to cast its fate with compiler writers, Transmeta decided that its chips would natively run essentially only one application: a dynamic x86 emulator.
Of course, emulators have become synonymous with “slow,” so Transmeta called its emulator a “code morphing engine” to create the illusion that its “Crusoe” chip really wasn’t emulating x86.
Nevertheless, Transmeta’s emulator, deployed with its first generation "Crusoe" line of processors, is very sophisticated.
At POST, 16MB of system memory is set aside for use as a “translation cache” and to hold the Code Morphing software. Transmeta’s emulator must first translate all x86 instructions it encounters into native Crusoe instructions before it can run any PC programs. This translation step imposes a very significant performance hit. To eliminate the translation overhead, recently translated code is stored in the “translation cache.” If the same x86 code is encountered again, the translated material is simply loaded from the translation cache. Transmeta’s emulator will also utilize idle CPU cycles to optimize translated code to extract better performance in case the same code is accessed again.
Code Morphing software also employs heuristics to chose among a set of execution options for code that it encounters. In some cases, x86 code will simply be interpreted, through translation that Transmeta refers to as "very simple minded code generation", to dynamic feedback optimized translations.
The Crusoe also has explicit hardware support for the Code Morphing engine, improving instruction throughput. For instance, the Crusoe is designed to handle the x86 ISA's precise exception semantics without constraining speculative scheduling. This is accomplished elegantly by shadowing all registers holding the x86 state. Only when a molecule completes without exception are the working registers committed to the shadow registers. Otherwise a rollback occurs and each x86 instruction is then executed singly to determine the precise location of the exception.
Alias hardware also helps the Crusoe rearrange code so that data can be loaded optimally.
===================================
The Transmeta Crusoe TM5800
Transmeta originally had hoped that the “Crusoe” would be as fast, or even faster than other competing x86 chips. However, this hope was soon dashed.
In fact, the first Crusoes were so abysmally slow that they were quickly supplanted by more expensive chips sporting twice the Level 2 cache. Even though the original Crusoes boasted large 256kB L2s, the caches were not large enough to hold the entire translation engine, causing the caches to thrash unmercifully. Consequently today’s TM5800 has a mammoth 512kB L2 cache to partially address this problem while the upcoming “Astro” will have an even more gigantic 1MB L2.
However, even with its large L2, the TM5800 is no track star. In fact, on many applications the only processor slower than the TM5800 is the TM5600, its ancestor.
Dave Ditzel has been a proponent of simple processors for a very long time. In fact, Ditzel was one of the major figures behind RISC. While RISC processors are no longer considered the panacea they once were, RISC-like features are common in many of today's processors. Even chips traditionally antithetical to RISC ideology such as x86 processors, now incorporate many RISC ideas. The AMD Athlon XP is a good example of this featuring basically a hardware x86 decoder bolted onto a very efficient out-of-order RISC-like core.
Ditzel's quest for simplicity is continued with his fascination of VLIW. Consequently, the TM5800 is a pretty simple chip. The TM5800 has two integer units, a single FPU unit, a memory load/store unit and a branch unit.
VLIW processors should not need extremely deep pipelines since the decoding and instruction scheduling are large handled beforehand in software. The TM5800 has seven integer pipeline stages. Floating point processing uses ten stages.
A common misconception is that a VLIW chip can execute any four native instructions simultaneously. For this to occur, a 128-bit VLIW processor would have to have four of each type of instruction unit, in which case we would have essentially a multi-core VLIW processor.
With the ability to issue, at a maximum, only one floating point instruction per clock cycle, the TM5800 is not going to be very swift in floating point intensive applications. Compared with the Athlon XP, which can chomp on up to three floating point instructions at once, the TM5800 will be a tepid performer even if its "Code Morphing Engine" manages to reach the efficiency of a hardware instruction decoder.
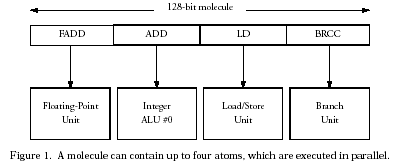
From "The Technology Behind Crusoe Processors by Alexander
Klaiber, Transmeta
The Crusoe's 128-bit long instruction word is called a "molecule." Each of the up to four 32-bit instructions that can be contained in a molecule are referred to as "atoms." Each molecule is executed in order, removing the complexity of an out-of-order engine. Instead, the TM5800 relies upon it's x86 emulator to schedule atoms to extract parallelism.
Unfortunately, its dearth of execution units combined with the complexity of routing decoded x86 instructions often leaves many if not most Crusoe molecules only partially populated, executing as few as one atom per clock cycle.
===================================
Strengths
The TM5800 does have its strengths. As noted above, VLIW is a proven strategy for handling DSP (digital signal processing) tasks. True to form, DSP-style chores are the TM5800’s forte. This includes various types of encoding and decoding jobs as well as streaming chores that move large amounts of data with minimal instruction diversity, and redundant, parallel (primarily integer) processing.
Interestingly, the TM5800’s strong points closely track those of the Intel Pentium 4. However, even at its best the TM5800 is not a stellar performer. Only on rare instances does the TM5800 approach similarly clocked Athlons and Pentium IIIs in performance. Much more often, the TM5800 is significantly slower than the VIA C3-Nehemiah.
===================================
Weaknesses
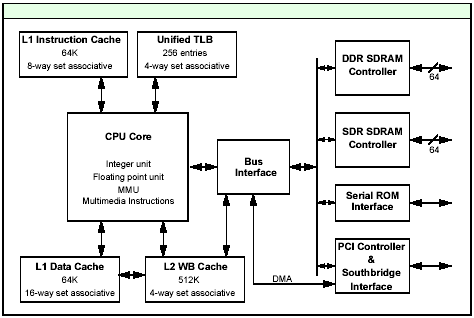
Crusoe TM5800 block diagram (from Transmeta
product brief).
Transmeta’s TM5800 is rife with weaknesses. Referring to the block diagram above, these include:
Crusoe can only access South Bridges through the shared PCI bus: this means only obsolete south bridges can be used. Consequently, I/O intensive applications will tank on Crusoe. The TM5800 has an integrated north bridge. This north bridge only exposes a PCI interconnect to the south bridge. Modern chipsets like the VIA CLE266 have much higher bandwidth interconnects enabling far better performance with hard disks, PCI devices and networking, especially when performing several different south bridge operations at the same time. The TM5800 is a very poor choice for servers due to its inherently low hard drive performance especially when multiple disk transfers occur at once together with network activity.
No AGP support can hammer performance on 3d games and many 2d intensive applications. The TM5800’s integrated north bridge does not provide an Advanced Graphics Port of any kind. This means that the PCI bus is further burdened with handling the graphics I/O for the system as well as all of the south bridge work. Additionally, texture transfers and many 2d graphics operations will be slowed tremendously by having to go through the tight PCI bottleneck.
128-byte L2 cache line can annihilate performance on branchy code or code accessing noncontiguous small data items. The TM5800 has a shockingly long 128-byte L2 cache line. What this means is that the smallest amount of memory the chip can pull in at any time will be 128 bytes. Even if only one byte is needed, the chip will have to fetch an entire 128 bytes. Needless to say this dramatically reduces bus utilization efficiency for many programs. Transmeta implemented this measure because a long cache line helps improve bandwidth which the chip sorely needs in order to pull in blocks of translated code. Unfortunately, branchy code or code that accesses small items from random memory locations will suffer greatly. This is a great contributor to the Crusoe’s very poor performance in many business applications.
Inefficient memory access degrades performance. A little known fact is that the Crusoe has two integrated memory controllers, one supports DDR SDRAM and the other supports SDRAM. The DDR SDRAM controller is intended for soldered down memory to hold the translation cache while Transmeta recommends using the SDRAM controller for expansion memory since the DDR SDRAM controller is limited to two banks of memory (1 DIMM). Needless to say, SDRAM is a poor match with the Crusoe and undermines the processor’s potential in bandwidth intensive situations.
Cache thrashing occurs in many real world applications. Although the TM5800 has a very large L2 cache, it is still insufficient to hold both the translation software and translated code. This promotes cache thrashing on branchy Windows code as is common in business and Internet applications. Transmeta is aware of this problem and will address it in the 100mm^2 Astro featuring a 1MB L2 cache.
Translation overhead kills performance in many real world applications. Even though Transmeta reserves 16MB of main memory for a translation cache, large footprint OOP code (as is used in Windows COM-based applications) will not be able to fit in this amount of memory. This ends up defeating the translation cache. The user winds up paying the translation penalty over and over in terms of pauses and sluggish system response.
Limited clockspeed potential. The fastest TM5800 tops out at 1GHz.
No SMP support.
No SSE. In general, the TM5800 runs applications optimized for SSE much slower than competitive chips like VIA's C3-Nehemiah.
Compatibility is suspect. Crusoe platforms have been notoriously problematic to benchmark because many benchmarks fail to execute or do not run correctly. For instance, the TM5800 1GHz Tablet PC would not run the SysMark2000 Paradox, or Photoshop tests and experienced many failures in Bryce 4, CorelDraw, and Netscape Communicator. The system also would not run Content Creation Winstone 2003, 3dMark 2000, Expendable and other tests.
===================================
Performance Examples
Viewing only common synthetic benchmarks can lead to mistaken conclusions regarding the performance of the Transmeta TM5800. Most of the synthetic tests thrashed about on enthusiast sites have small memory footprints for both code and data. Additionally, many tests loop numerous times over the same code and often even over the same data.
This benefits the Crusoe TM5800 on several levels. Crusoe's relatively large caches can often completely hold many synthetic tests along with their data. Looping many times over the same code will soften the impact of Crusoe's dynamic translation engine. Finally, cached translations are almost guaranteed to be utilized since synthetic tests are usually small and simple.
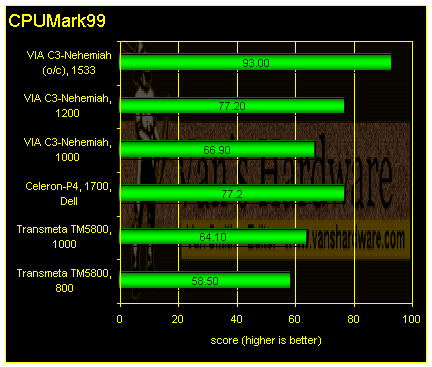
On CPUMark99, the TM5800 is competitive with both the Celeron-P4 and the VIA Nehemiah, falling only slightly behind these rivals. However, the overclocked 1.53GHz VIA C3-Nehemiah does stand out.
The TM5800's strengths and the VIA C3-Nehemiah's weaknesses converge in SuperPI. A 1GHz TM5800 is almost as fast the 1.7GHz P4-Celeron and about 2.5-times quicker than a 1GHz C3 on this benchmark that calculates pi out to 1,000,000 digits.

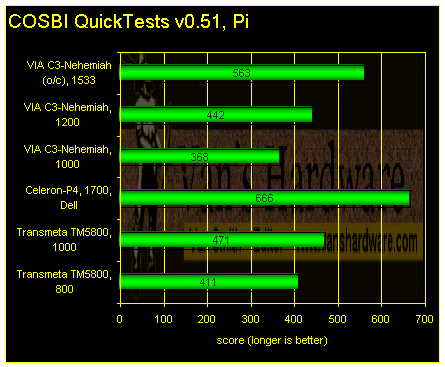
Newer versions of COSBI QuickTests also have a pi calculation benchmark. The algorithm used was borrowed, with permission, from Ray Lishner, the renowned author of Borland Delphi books such as Delphi in a Nutshell.
The TM5800 remains competitive on this test, but the C3-Nehemiah fares much better.
SysSoft Sandra is one of the most commonly used synthetic tests among webheads. Although we have had issues with Sandra in the past, Adrian Silasi has been responsive to most of our criticism. For instance, Adrian incorporated our suggestions to report the Pentium 4's true FPU performance (instead of only SSE2 results). Sandra also now provides optimized bandwidth routines for processing families outside of Intel.
Sandra delivers a set of quick and dirty tests that are useful as long as the evaluator understands the limitations of Sandra's benchmarks.

On Sandra2002, the TM5800 provides scores roughly on par with the VIA-C3 on the ALU, FPU and floating point bandwidth tests.
However, on all other tests the TM5800 trails badly. The worst Sandra test of all for the TM5800 is the floating point multimedia benchmark where the C3-Nehemiah is about six times faster. This is largely due to the TM5800's lack of any floating point SIMD engine like SSE or "3DNow!".
Even though the Crusoe supports MMX, the TM5800 still is only about half as fast as the slowest VIA C3-Nehemiah on Sandra's integer multimedia test.
The TM5800's integrated memory controller doesn't seem to help much on the integer bandwidth test where the TM5800 is only slightly better than 50% of the performance of the VIA C3-Nehemiah.
Comparisons with the P4-Celeron on Sandra are even worse across the board, but the Intel chip gulps far, far more power than either the TM5800 of the C3. Also, in application level tests, the P4-Celeron does not fare nearly as well.
But, sadly, neither does the Transmeta TM5800. In application level benchmark after application level benchmark, the TM5800 routinely underperforms even its competitors' slowest processors by non-trivial margins. Here are a few examples.
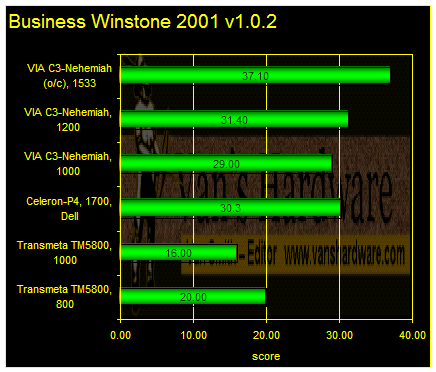
On Business Winstone 2001, the 800MHz TM5800 exceeds its 1GHz sibling largely because it is using the same 40GB 7200rpm ATA100 Seagate desktop hard drive used in all of the VIA systems. The P4-Celeron system also used a Seagate drive with identical specifications other than its 20GB capacity.
The 1GHz Transmeta system was a high-end Tablet PC using a 30GB notebook drive and 16MB NVIDIA GeForce2Go graphics.
All systems had 256MB of PC2100 DDR SDRAM. The VIA systems used integrated CLE266 graphics. The Dell system was based upon the Intel i845G and also relied upon integrated graphics.
Both Transmeta systems reserved 16MB of system memory for the translation cache, while the VIA systems set aside 32MB for video frame buffer.
The Transmeta systems enjoyed generally superior discrete graphics cores over the Intel and VIA platforms. As mentioned above, the 1GHz TM5800 Tablet PC had a GeForce2go with a 16MB dedicated frame buffer. The 800MHz TM5800 development system was aggressively tuned and used an ATi M6 Mobility Radeon with 8MB of embedded frame buffer memory.
As can be seen on Business Winstone2001 graph above, the two TM5800 systems follow far behind all of the other platforms in this comparison.
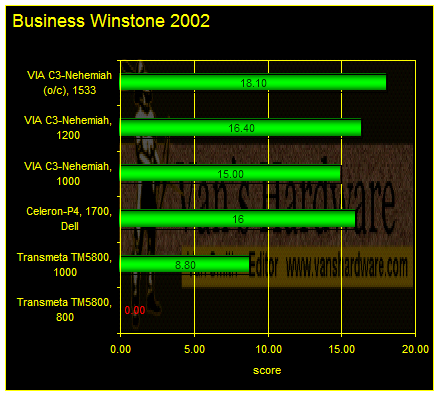
The 800MHz Crusoe system would not run BWS2002.
The situation does not change on Business Winstone 2002 with the 1GHz Transmeta system badly trailing its rivals. Worse yet, the 800MHz Transmeta system was not able to complete Business Winstone 2002.
Failures were much, much more common with the Transmeta platforms than the other systems in this comparison. Balky compatibility appears to be a real issue with the Transmeta TM5800 as we mentioned in our list of TM5800 weaknesses.
The floating point unit in the VIA C3-Nehemiah is that chip's biggest weakness. However, VIA's budget chips easily trump the Crusoe on both Content Creation Winstone 2002 and 2003. The VIA C3-Nehemiah's support of SSE certainly helps its showing on these tests.

The TM5800/1000 had a slow notebook drive that might explain its lower scores..
Unsurprisingly, the P4-Celeron dominates on CCWS2002, a contrived bundle of tests that stresses bandwidth, which the P4-family of processors have in abundance. Nevertheless, for many encoding tasks, the P4-Celeron is the clear leader among this group of chips. Applications that use SSE2 will push the P4-Celeron even farther into the lead. However, again, the P4-Celeron consumes a great deal more power than the other chips in this comparison.
Given the C3's weak FPU, it is startling that even the slowest of the VIA C3 systems beats the Transmeta systems in what should be the TM5800's saving grace.
In fairness to the C3-Nehemiah, the problems with its FPU throughput is more attributable to the in-order nature of the C3 design. Programs that do not schedule FPU instructions back to back will suffer less on the C3 than dense FPU code where the chip essentially stalls waiting for each FPU instruction to complete.
We thought Content Creation WinStone 2003, an even more P4 friendly test, might boost the Transmeta processors into the lead. But as is a common occurrence with Crusoe-based systems, neither of the TM5800 platforms would complete CCWS2003. As we mentioned before, we encountered many failures on the Transmeta systems.
The Crusoe is terrible at rendering web pages. The Netscape test below is the most favorable showing Crusoe was able to muster. From here, things get worse – much worse – for Crusoe on browser tests.
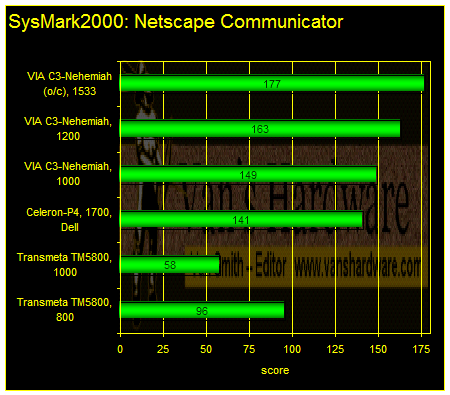
The TM5800/1000 system is configured for Tablet PC work.
But before we get to more browser tests, recall that the TM5800 relies upon its single PCI interface for all I/O. Such an arrangement will sink disk and video performance and is why all modern chipsets deploy high-bandwidth interconnects to link north and south bridges and AGP to open up bandwidth to graphics. Combined with translation overhead and a 128-byte cache line that will quickly saturate the bus with unneeded data, the Crusoe TM5800 is a very poor choice for databases.
The Paradox results below support this assertion.
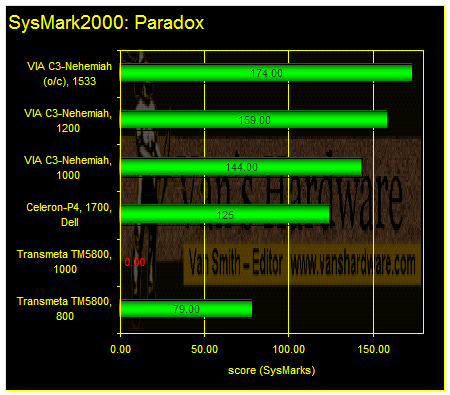
The 1GHz TM5800 Tablet PC would not run the SysMark2000 Paradox test.
Although we tried many times, we could not get the 1GHz TM5800 to complete the Paradox test. The 800MHz system that did complete the Paradox test is only about half as fast as the slowest VIA-C3 Nehemiah system.
Crusoe’s deficiencies are perhaps most clearly demonstrated in OfficeBench. In the Internet Explorer 6 (XP) test, even VIA's slowest C3-Nehemiah is four times faster than the fastest Crusoe.
Worse still, the Crusoes were outfitted with superior graphics solutions. For example, the 1GHz TM5800 Tablet PC system used a GeForce 2 while all of VIA's and Intel's platforms in our comparison utilized integrated graphics.
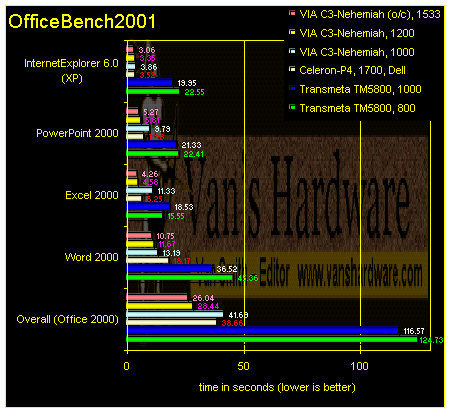
Why does the TM5800 perform so poorly on all of these tests using mainstream business applications? Combined with translation overhead, slow disk I/O and PCI graphics, Crusoe’s 128-byte L2 cache line certainly takes its toll.
The impact of the 128-byte L2 line is illustrated in COSBI MemLatency. This program reads and writes 4-byte integer array elements over an 8MB area.
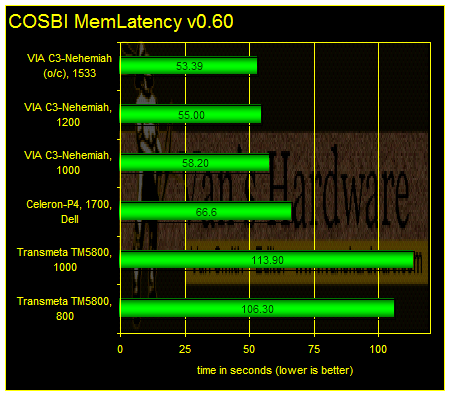
The 800MHz TM5800 development system slightly outperforms the 1GHz Tablet PC. The memory timings for the development system are clearly set to a more aggressive level.
Even though Crusoe has an integrated memory controller which should greatly reduce memory latency, effective latencies seen when trying to access noncontiguous array elements are terrible thanks to Crusoe’s 128-byte line.
In contrast, while VIA's C3-Nehemiah uses an external “traditional” memory controller with inherently greater latencies, it is roughly twice as fast on COSBI MemLatency thanks to its more rational 32-byte cache line. With a cache line ¼ the size of Crusoe’s, bus utilization is much more efficient.
But what about games? Since it was not possible to change the graphics controller for the Transmeta platforms, we cannot have an even comparison, but we can look at the "CPU Speed" test of 3dMark. On this tests, the rendered area of the screen is reduced greatly so that the CPU becomes the main performance limiter.
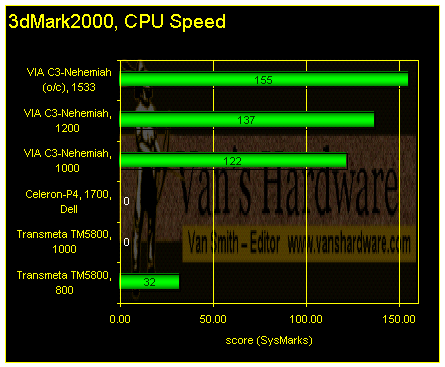
3dMark2000 would not install on either the 1GHz TM5800 system or the Dell P4-Celeron. However, the test installed and ran fine on the other platforms.
Dismally, the Transmeta TM5800 development system delivered only about a fourth of the score of the slowest VIA platform.
===================================
Benchmarks Don’t Tell the Whole Story
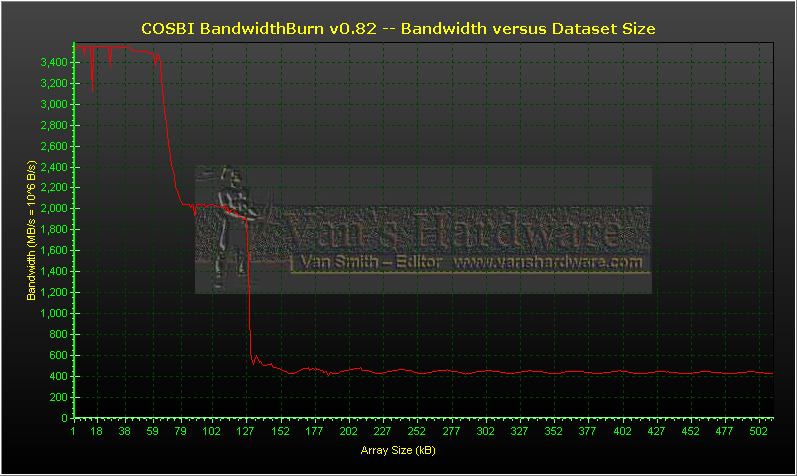
Sometimes Crusoe appears to cheat on benchmarks. When running multiple iterations of the same test, Crusoe’s dynamic optimizations appear to eliminate subsequent iterations if they are duplicating the work of the first iteration. This seems to be demonstrated in COSBI BandwidthBurn where clearly invalid results are reported on all Crusoe platforms. All other processors execute the test properly.
Fortunately, BandwidthBurn reports results in enough detail so that artifacts of Crusoe’s dynamic optimization are easily seen. However, this raises the obvious concern that other benchmark scores are being artificially inflated through Crusoe’s dynamic optimizations.
Below you can see the bogus results that Crusoe’s x86 emulator yields, followed by normal results obtained on a VIA C3-Nehemiah.
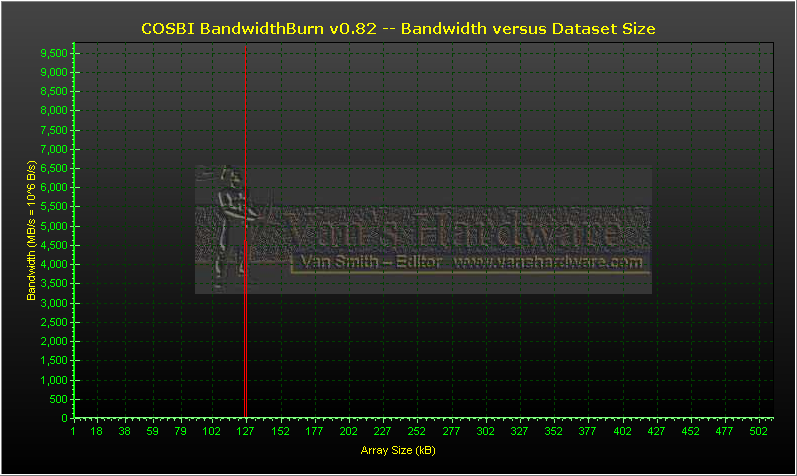
TM5800-1000
VIA C3-Neheniah (c5xl), 1333
Interestingly, the Crusoe does not behave the same way on each test and sometimes produces proper results on BandwidthBurn.

TM5800-1000 can
occasionally produce proper results and looks rather slow when it does.
Memory bandwidth for the TM5800 is a mixed bag. Although the TM5800 gets a little better score on BandwidthBurn than VIA's C3, we have already seen where Transmeta's chip trails badly in SisSoftware Sandra . The Sandra problems are likely due to the TM5800's lack of SSE prefetching, cache-bypassing support which both the P4-Celeron and the VIA chips feature. Even on BandwidthBurn, the throughput of main memory is surprisingly low considering that the TM5800's uses an integrated DDR SDRAM controller (SDRAM was not used on any of these tests in order to show the TM5800 in the best light possible).
Most artificial benchmarks have small memory footprints and iterate many times over the same workload. Such tests play to the Crusoe’s strengths. By iterating many times, Crusoe’s translation overhead is minimized. Crusoe’s large caches can often completely hold the translated benchmark as well as its data.
However, the “real world” vividly exposes the Crusoe’s flaws. Application level benchmarks like those shown above expose the Crusoe in a much less flattering light than small, unrealistic, synthetic tests.
===================================
Power Saving
When Transmeta first discovered that its initial high performance expectations for Crusoe were astronomically unrealistic, the company scrambled to find a saving grace to an architecture that essentially meant the company’s survival (not to mention millions upon millions of investment dollars).
Out of this panic came the realization that Crusoe consumes little power. Of course a big part of the reason for this was that many of its executions units were sitting around doing nothing most of the time, but, no matter, it was a spin and it was at least outwardly positive if constructed properly.
Compared with the 100W oyster cooking Intel Pentium 4, yes, Crusoe uses very little power and is a much better solution for small and light notebooks. Crusoe’s LongRun was the first mobile technology to deploy dynamic frequency and voltage changes, which greatly reduces power consumption. However, since LongRun’s introduction, AMD, Intel, and now VIA have caught up and are all providing very similar power saving schemes.
Yes, Crusoe is a better small and light notebook solution than the Intel Pentium 4, but compared with chips like the VIA C3-Nehemiah, the TM5800 has no real power saving advantage and is usually slower when running common applications.
The VIA C3-Nehemiah has a maximum power draw at 1GHz of 11W. This value should decrease significantly with an updated core due shortly dubbed "C5P". TM5800 has a published max power draw varying from 6.5W to 9.5W as shown in the chart below.
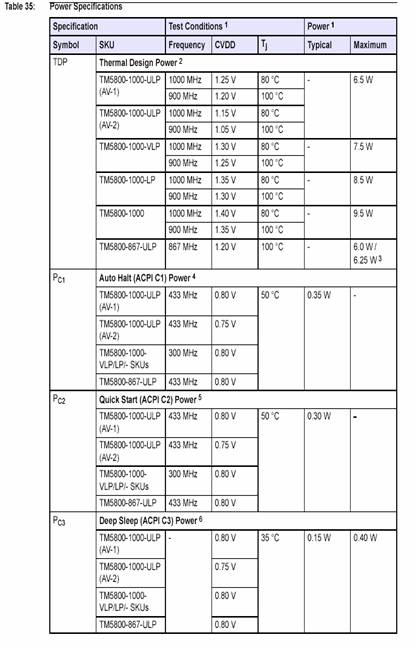
Of course “typical” power is a focus of raging manipulation by marketing departments, but right now, with "PowerSaver," the VIA C3-Nehemiah should consume around 1-2W. This situation will improve dramatically with an upcoming Nehemiah revision dubbed "C5P." If taken in consideration with the power draw from the rest of a typical notebook (e.g. LCD display and backlight, memory, video controller, hard drive, wireless NIC, etc.) the CPU’s contribution is only a minor overall component.
For comparisons of power saving technologies, we expect that a focus on real world battery life tests will reveal little difference between the Transmeta TM5800 and VIA C3-Nehemiah-based notebooks.
===================================
Summarizing the TM5800
As far as servers, notebooks, desktops and tablets are concerned, the Transmeta TM5800 is clearly the wrong tool for the job.
Constantly running its x86 emulator, the TM5800’s translator overhead makes everyday use painful. Menus open at glacial speeds. Internet web pages usually render properly -- but only eventually. Business applications are sluggish enough to infuriate the most patient user.
The TM5800’s 128-byte L2 cache line brings database operation to its knees. Reading a single byte means that the TM5800 still has to fetch an entire 128-bytes. The slow SDRAM interface is quickly overwhelmed with 128-byte requests.
Limited to obsolete south bridges because of its reliance upon the PCI bus for all I/O (including graphics!), the TM5800 is a very poor choice for servers where the PCI bus will be woefully overloaded, particularly on concurrent network requests hitting multiple drives.
While the competing CPU architectures like VIA's C3-Nehemiah will likely see clock speeds at or above 1.33GHz (c5p may run even faster), the TM5800 tops out at 1GHz.
With graphics solutions limited to the PCI bus, expect to see lots of pauses in texture intensive 3d games. Many 2d intensive applications will also crawl thanks to the PCI bottleneck. And, pity those who actually try to access the disk or network while playing games or running complex Windows programs that paint the screen frequently, all of which will be fighting for the puny PCI bus.
Of course, the Crusoe TM5800 is greatly disadvantaged on programs and games that have SSE optimizations. Photoshop is but one example.
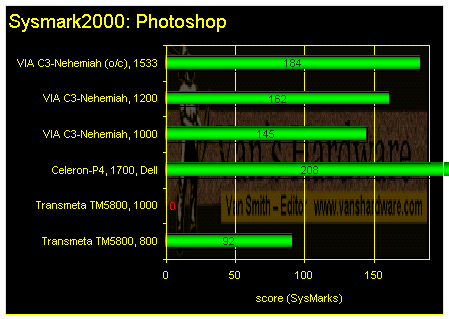
The Photoshop benchmark in SysMark2000 is yet another test
that failed to run on a Crusoe platform.
Some benchmarks do run pretty well on Crusoe. If the benchmark iterates many times then Crusoe’s translation penalty can be neutralized. Many benchmarks have small memory footprints and can fit in Crusoe’s mammoth cache.
However, we have seen that the Crusoe x86 emulator’s dynamic optimizations might cheat on benchmarks. This was demonstrated in COSBI BandwidthBurn. On how many other benchmarks does this occur? That is a difficult question to answer, but a valid one to ask.
Power saving advantages of the Crusoe are largely overblown given the overall power requirements of a computing platform. We believe that a concentration on notebook battery life tests will yield little difference between the Crusoe TM5800 and rival processors from AMD, Intel and VIA.
People considering the purchase of of a TM5800-based system would be wise to try the system for an extended period before committing money. The sluggish performance of Crusoe systems is enough to prompt even the meek or the proper to consider foul language. Opening programs, displaying menus, scrolling through documents, viewing web pages - just the day-to-day tasks that we all perform progress at geological paces on Crusoe-based systems.
Of course, it also appears that spotty compatibility is an issue with Crusoe. Specific applications should also be tested before taking the plunge and buying a TM5800 notebook or Tablet PC.
As a final thought, revisit the Crusoe’s performance on web browsing. The Crusoe’s abysmal showing in the Internet Explorer 6 test of OfficeBench2001 is for real. To demonstrate this, simply load a web page into the same browser on the Crusoe and on a competing platform and refresh the page. Typical results for Internet Explorer in Windows XP are shown below.
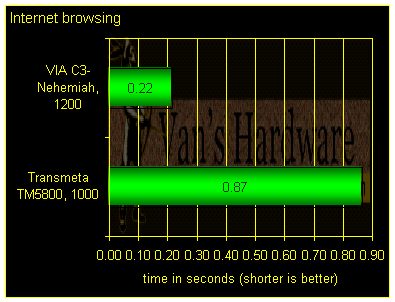
In this case, the humble VIA C3-Nehemiah is about four times faster than the Transmeta TM5800. For some web pages this performance differential might not be much of an issue, but for extended web browsing the sluggishness can quickly become infuriating. Even though the TM5800 Tablet PC is probably the most “tricked out” platform the TM5800 will ever see, browsing the web can be too much for it to handle.
In our comparisons, the P4-Celeron really does not compete with either the TM5800 or the C3-Nehemiah because the Intel chip consumes much more power. However, the P4-Celeron is much more robust for gaming and encoding.
But before anyone should choose the Crusoe TM5800 over a VIA C3-Nehemiah or any other CPU, they should seriously ask themselves what they are going to be doing more: browsing the Internet, reading email, playing games, and working in Office or running Whetstone and CPUMark99. For the day to day work that most people conduct on their notebooks, choosing a C3 should be a no-brainer for a solution in a low cost notebook. And if more processing power is needed, both the Intel Centrino and the AMD Athlon XP-M are extremely formidable, albeit at somewhat higher costs (the Centrino is actually much more expensive).
===================================
The Transmeta Astro: Last Hope for VLIW
Earlier in this article, we listed a sizeable number of flaws for the TM5800. Transmeta has been extremely systematic in addressing the weakness of the TM5800 with the very ambitious "Astro," the next generation Transmeta CPU due for release anytime now.
The chart below summarizes the major differences between the TM5800 and the Astro, known formally as the TM8000.
| tm5800 | tm8000 | |
| chipset interconnect | shared PCI bus | 400MHz HyperTransport |
| graphics interconnect | shared PCI bus | AGP 4x |
| L2 cache | 512kB | 1MB |
| memory controller | SDRAM + DDR SDRAM (limited to 1 DIMM) | DDR SDRAM (up to PC3200) |
| clock speed | up to 1GHz | >1GHz (probably less than 1.33GHz) |
| VLIW instruction length | 128-bits | 256-bits |
| maximum number of 32-bit instructions per clock cycle | 4 | 8 |
| MMX | yes | yes |
| SSE | no | likely |
| SSE2 | no | possible |
| symmetric multithreading | no | plausible |
| number of execution units | 5 | 10? |
| die size | ~55 mm^2 | ~100 mm^2 |
| numer of transistors | 36.8 million | ~70 million? |
The TM8000 is a much more advanced chip than the TM5800 and will, with no doubt, bring significant performance advantages over its predecessor. Many more execution units will be available to keep its doubled 256-bit VLIW molecule populated. Each 256-bit VLIW molecule can now handle eight 32-bit instructions at once.
Transmeta has released very few TM8000 details, but we can make a few educated guesses of its capabilities. While SSE and SSE2 functionality have not been disclosed, the addition of a second FPU is almost certain. Given a second FPU, SSE should be possible to implement at the code morphing level. SSE2 is a more remote possibility.
Full utilization of all four "atoms" in the TM5800 appears to be the exception rather than the rule. One way that Transmeta might be hoping to exploit the eight-word TM8000 is by implementing symmetric multithreading (SMT -- think HyperThreading) in its Code Morphing engine. If this is the case, Transmeta might expose the TM8000 to the OS as if it were two TM5800s.
SMT should be a relatively simple technology to deploy on the TM8000 and would likely reap much more significant gains than what is seen on Intel's Pentium 4 under HyperThreading.
Originally, Tranmeta claimed that the TM8000 would debut over 1GHz, but since then the company has grown mum on final clock speed capabilities. And although originally expected to ship sometime after July 1 with system availability soon afterwards, Transmeta has recently backed off this date. In a May 29th PC World interview, Transmeta's Dave Ditzel was quoted as saying, "We have not said anything about availability and, based on what happened with the TM5800, maybe we won't make any predictions." No doubt, such a flaccid commitment from the company's CTO makes beleaguered long-time Transmeta investors shift uncomfortably in their seats.
Also worth mentioning is that Transmeta was caught manipulating benchmark demonstrations in favor of the TM8000. While initial reports of Transmeta's Astro were positive of Transmeta's performance demonstrations, AnandTech discovered that the systems had been configured to benefit the TM8000. The tests involved opening Microsoft Office applications while loading large files. All of the tasks were limited by hard drive throughput.
The benchmarks weren't performed very scientifically at all; they involved manually timing the start-up of Microsoft Word and PowerPoint as they attempted to open multi-megabyte files. In all cases the Astro was faster than the mobile Pentium 4 however what invalidated the results was the fact that Transmeta outfitted the Astro system with a desktop hard drive and the Pentium 4 laptop had a slow notebook drive.
If a series of unbalanced hard drive tests is the best performance demonstration that Transmeta could come up with, then the TM8000 may still be mired in the some of the more sticky VLIW issues we brought up with the TM5800.
We expect that on compute intensive tasks, the TM8000 will see a best case increase of 100% over the TM5800 at the same clock speed. Advances under most conditions will be significantly below this level.
Under multi-threaded, I/O intensive activity, Astro should see performance jump at times by as much as 300% or more. The Astro will be far, far better suited for servers than the TM5800.
Unfortunately, these performance gains were made at the expense of many millions of transistors and a die size (~100 mm^2) around twice as big as the TM5800 (~55 mm^2) and much larger than both Intel's Pentium-M (~83mm^2) and AMD's Athlon XP-M (~87mm^2). While Astro might occasionally match the performance of a Pentium-M or Athlon XP-M at the same clock speed (particularly on multi-threaded apps if SMT is implemented in the TM8000), both competing chips scale to much higher clock speeds and are cheaper to produce.
Power saving advantages over the Pentium-M and Athlon XP-M are also moot for the same reasons that the TM5800 does not hold real life benefits beyond its competitors.
Cost considerations will prohibit the TM8000's migration into the TM5800 space. With a die size nearly twice as large as the TM5800, each chip will cost around 3x the price to fabricate.
Unless there are unforeseen technological advances in the TM8000, the chip, although a clear advancement beyond the TM5800, will be relatively expensive to produce while delivering substantially worse performance than its potent competitors in the performance notebook space where Transmeta will be forced to market it.
===================================
Conclusion
Dave Ditzel was one of the seminal figures behind the RISC movement, a computing architecture ideology that is passé today, although its impact has greatly influenced modern processor designs. Through Transmeta, Mr. Ditzel has been an unwavering proponent of VLIW, a movement which can be viewed as an evolutionary step beyond RISC concepts. Unfortunately, the Transmeta experiment might prove to be VLIW's tragic end, at least as an attempt at general purpose microprocessors.
Although the idea of an optimizing software decoder scheduling parallel instructions for a simple, very long instruction word core is seductive, the TM5800 has been a dismal performer. While the TM8000 wonderfully addresses the TM5800's manifold flaws, it does so at great expense, pushing the chip into a market space where it likely will not be performance competitive.
Transmeta's processors fall short of two major promises made by original VLIW champions. Transmeta's chips cannot match the performance of competing products on the majority of popular applications. To boost performance, Transmeta has had to resort to measures that bloat die sizes and transistor counts to a degree that significantly eclipse those specifications of products in the same performance spectrum.
With advances in power saving technologies by AMD, Intel and VIA, Transmeta's products do not offer advantages that will significantly extend battery life in notebooks where the CPU's contribution to overall power consumption is minor.
At its historical burn rate of $20-$30 million per quarter, we project that Transmeta has about a year before it will become insolvent. Transmeta's financial results announcement scheduled for July 17th will be telling.
The only hope that we see for this daring (maybe "brash" is more accurate) little company, is a benevolent takeover. Even so, its technology is not persuasive enough to extend its current product lines targeting the x86 notebook and desktop spaces. The only areas where Transmeta's technology makes sense are in narrowly defined embedded applications.
It appears that VLIW will end up being a failed experiment in the general purpose microprocessor arena, a fate much worse than Ditzel's other baby, RISC, whose legacy lives on in almost every modern CPU.
===================================
Pssst! We've updated our Shopping Page.
===================================
Copyright 2003, Van Smith
===================================